
Statistical Learning Theory
-
The goal of statistical learning theory is to understand the learning mechanisms of modern machine learning algorithms and to use this knowledge for the design of new learning algorithms. In our group we have recently focussed on the following aspects:
- Kernel-based learning algorithms
-
Kernel-based learning algorithms such as support vector machines are a widely-spread class of off-the-shelf learning algorithms, which often produce state-of-the-art results for unstructured data sets. We have been investigating all aspects of these algorithms including their statistical analysis, their approximation capabilities, and efficient modifications for large-scale data sets.
- Cluster analysis
-
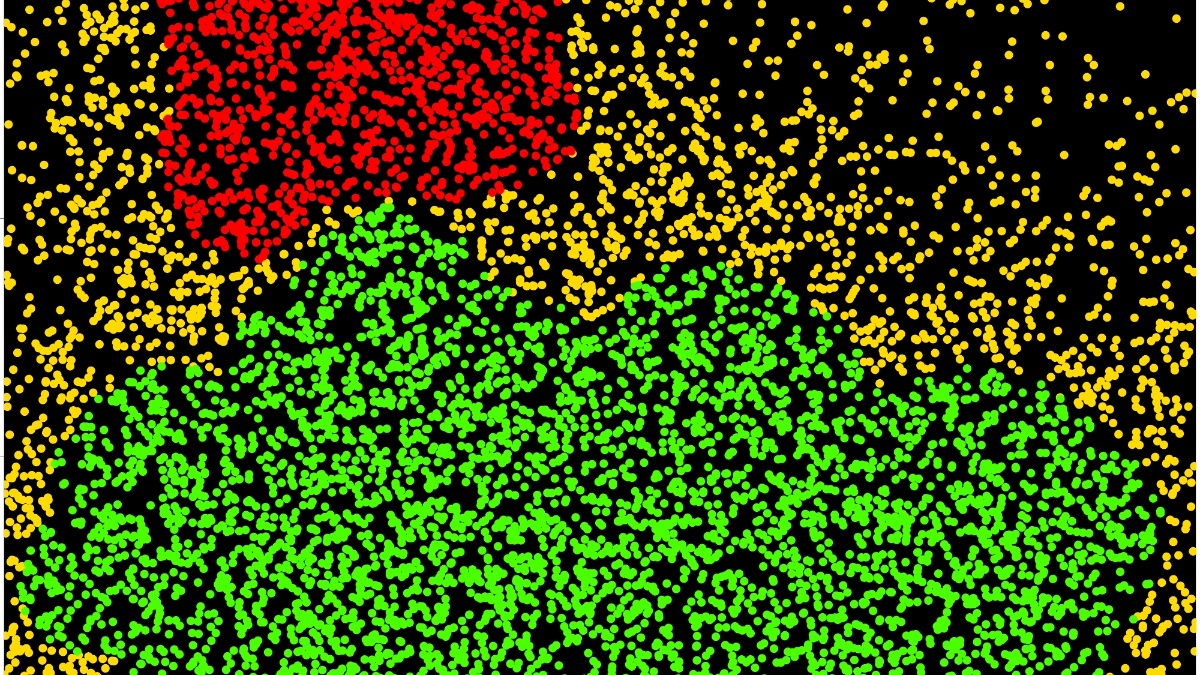
Cluster analysis is a core task in data exploration. Among the several existing notions for clusters we have mainly focussed on the statistical analysis of density-based clustering algorithms.
- Efficient learning algorithms
-
The computational requirements of many successful learning algorithms can become prohibitive for large-scale data sets.We have been using our statistical insights to design new algorithms that require significantly less resources without sacrificing statistical guarantees.
- Loss functions and their risks
-
Most supervised learning algorithms optimize an objective function whose main ingredient is an empirical error term, where the error is measured with the help of a loss function. The choice of the loss function determines the learning goal and thus the outcome of the learning process. We have been interested in the relationship between loss functions and learning goals, asking, for example, which learning goals can be expressed by a loss function.
- Learning from non .i.i.d. data
-
The existing statistical analysis of machine learning algorithms assume in most cases independent, identically distributed (i.i.d.) data. In many cases, however, this assumption is violated. We have been focussing on learning from both dependent random data, and deterministic data.
- Reproducing kernel Hilbert spaces
-
Reproducing kernel Hilbert spaces do not only play a central role in kernel-based learning algorithms but are also an important notion in various other areas of mathematics. We have been investigating several aspects of these spaces and their interactions with probability measures.
Cluster Analyse: Some Examples

Observed data

Estimated clusters

Observed data

Estimated clusters

Observed data

Estimated clusters

Observed data

Estimated clusters

Observed data
Estimated clusters